Shodan Update: May 2024
Integrations
The following new or expanded integrations are now available:
Crowdstrike Falcon LogScale
We've added a new article on how to integrate Shodan Monitor with LogScale using their Ingest API. The integration lets you store all information that Shodan collects for monitored assets and makes them searchable through LogScale: Learn More
This is similar to the integrations we already offer for Splunk and Gravwell.
Kubernetes
We've forked the previous Kubernetes integration for Shodan Monitor and are now making it an official Shodan integration. It's now as simple as running 3 helm commands to get it fully running on a K8s cluster:
# Add the shodan-monitor-kubernetes helm repo$ helm repo add shodan-monitor-kubernetes "https://shodan-public.gitlab.io/shodan-monitor-kubernetes"$ helm repo update
# Install the shodan-monitor-k8s integration$ helm install --set shodanApiToken=SHODAN_API_KEY shodan-monitor-k8s shodan-monitor-kubernetes/shodan-monitor-k8sFor more information check out the help center article: Learn More
Graylog
We've written a new integration for Graylog to perform IP enrichment using the Shodan API or the InternetDB API. The Shodan API adapter requires an API key whereas the InternetDB API can be used for free without an API key. Learn More
Microsoft Copilot for Security
"Check the IP address 1.1.1.1 using Shodan". We're excited to announce the Shodan plugin for Microsoft Copilot for Security:
https://learn.microsoft.com/en-us/copilot/security/plugin-shodan
The Shodan plugin, alongside many others, are now available in public preview. Learn More
Data Improvements
Changelog
The Datapedia now has a Changelog section that shows the changes in its schema and offers an RSS feed that you can use to get notified when we update the schema.
ai Tag
We've started tagging AI-related services with the ai tag. For example, services that are used to self-host LLMs would receive the ai tag.
IoT Expansion
We've added dozens of new detections for various IoT products so they have the iot tag as well as service-specific metadata when available. For example, the Shodan crawlers now identify Raspberry Shake devices.
Vulnerability Information
Introducing the CVEDB API
We've launched a new website and API that provides free, fast vulnerability lookups. The vulnerability information contains EPSS, KEV, multiple CVSS scores and more. It's the same API that we use internally to perform vulnerability enrichment on the banners but the CVEDB API contains additional properties.
EPSS and KEV
With the launch of CVEDB API we're also introducing 2 new properties in the vulnerability object on the banner: epss and kev:
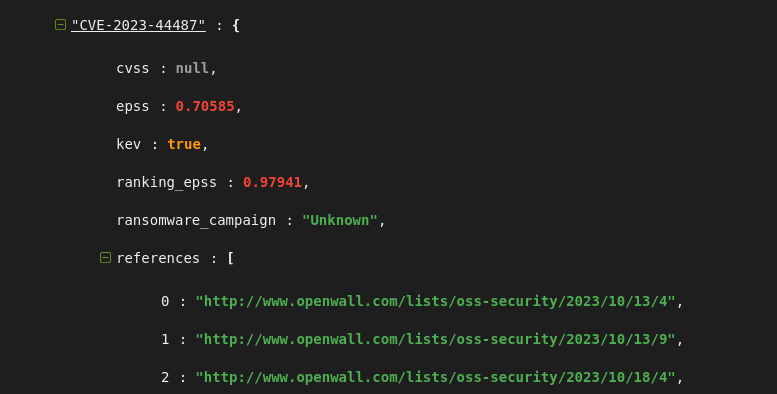
Breaking Change to cvss
The Shodan banners store vulnerability information in the top-level vulns property. Within that property are a list of (potential) vulnerabilities that have been identified based on the software and version. Those vulnerabilities have a cvss property that so far has been pinned to CVSS version 2. For legacy reasons, we've continued to use CVSSv2 even though it's been deprecated by NVD and isn't available for newer vulnerabilities. However, we've decided that it's time to move on and change the way we store CVSS scores and unfortunately that requires potentially breaking changes. The new system will work as follows:
There will be 2 properties:
cvssandcvss_versioncvsswill store the score for a vulnerability using the latest version of CVSS. For example, if a vulnerability has both a CVSSv2 and CVSSv3 score then we would store the CVSSv3 score in thecvssproperty. If a vulnerability only has a CVSSv2 score then thecvssproperty would contain the CVSSv2 score.cvss_versionwill contain the CVSS version that was used to calculate thecvssscore.For legacy support, we will continue to offer a
cvss_v2property that will always store the CVSSv2 score (nullif it doesn't exist). We will offer that property for a year after which we will remove it and require usingcvssandcvss_version.
It's rare for Shodan to make breaking changes but we believe that the current way of storing CVSS scores doesn't scale and requires a change. For Enterprise customers that want more control over the vulnerability enrichment we recommend checking out the cvedb SQLite file.
Bugfix
There are 2 notable fixes that were applied which we would like to highlight:
Fixed Events API erroring out: if you tried out the Events API but saw an error message then your account was most likely impacted by the bug and that should be resolved. It was patched shortly after the last newsletter was sent out but if you have any issues consuming the Events API please let me know.
Fixed
scannertag not getting added: thescannertag is used to mark IPs that have been seen scanning the Internet. The data is sourced from our own honeypot network but due to a bug in the enrichment pipeline we hadn't been consistently adding the tag. For a list of available tags check out the Datapedia.
Bulk Data (Enterprise)
The following datasets are now available via the Bulk Data API. For convenience, the datasets can be downloaded via the Shodan CLI but for production deployments we recommend a tool such as aria2c because it can use multiple connections to download a single file.
Tip: Run
sqlite3 <file> .schemato see the schema for a given SQLite database.
CVEDB
The cvedb dataset is a SQLite database containing vulnerability information from NVD that powers both the vulnerability enrichment for the Shodan API/ website as well as the new cvedb.shodan.io API. The SQLite database is optimized for looking up vulnerabilities based on a CPE. Most of the details for a specific CVE are stored as a gzip-compressed JSON object in the compressed_cve_data property. In order to see the JSON you need to decompress the blob.
Quickstart
Download the database file:
shodan data download cvedb cvedb.sqlite.gzUncompress it:
gunzip cvedb-cvedb.sqlite.gzRename it to something more convenient:
mv cvedb-cvedb.sqlite cvedb.sqliteUse the
sqlite3tool to query it for test purposes:sqlite3 cvedb.sqlite
Example: Vulnerability Lookup
sqlite> SELECT cve_name, compressed_cve_data, epss, kev, '' || GROUP_CONCAT('cpe:2.3:' || part || ':' || vendor || ':' || product || ':' || version) || '' AS cpes, published_timestamp FROM cveXcpe WHERE cve_name = 'CVE-2014-0160' GROUP BY cve_name;The cveXcpe table is optimized for lookups by CPE so we need to concatenate and merge rows in order to get a single row with all the vulnerability information.
Example: Lookup vulnerabilities for Nginx 0.1.0
sqlite> SELECT DISTINCT cve_name, kev FROM cveXcpe WHERE product = 'nginx' and version='0.1.0';The above query will return the list of vulnerabilities for nginx version 0.1.0 and whether it's in the Known Exploited Vulnerabilities (KEV) catalog.
DNSDB
In addition to offering the DNS data in CSV we now also offer it as a SQLite database. As a quick recap, the DNSDB files contain the most recent 30 days worth of DNS data that Shodan has collected. We use that data internally for the monthly hostname-based scans and as a result the DNS data is geared towards finding hostnames that are actively running services. The DNSDB files are generated once a month from an export of our backend DNS database which is updated continuously throughout the month.
Example: Get a list of subdomains
The SQL query to fetch the information is simple:
sqlite> select hostname from hostnames where domain='shodan.io';The big advantage though is how fast the queries run when done locally instead of via an API. To give you an idea of the performance of the dnsdb.sqlite file here are some numbers for grabbing all the data for the amazonaws.com domain:
$ time sqlite3 dnsdb.sqlite "select count(*) from hostnames where domain='amazonaws.com'"4267421
real 0m0.193suser 0m0.142ssys 0m0.051s
$ time sqlite3 dnsdb.sqlite "select * from hostnames where domain='amazonaws.com'" > /dev/null
real 0m1.692suser 0m1.432ssys 0m0.260sThere are around 4.2 million records for the domain and it takes around 1.7 seconds to iterate over all of them using my personal laptop.
Example: Finding other websites hosted on the same server
We can use DNSDB to quickly identify other websites that are using the same public IP. For example, lets see which IPs that shodan.io is using:
Tip: Geonet could be used to lookup the IP for a website from multiple locations in case the IP changes depending on the client location.
sqlite> select * from hostnames where hostname='www' and domain='shodan.io';www|shodan.io|A|104.18.12.238www|shodan.io|A|104.18.13.238www|shodan.io|AAAA|2606:4700::6812:ceewww|shodan.io|AAAA|2606:4700::6812:deeAnd now we can query the ip_hostnames table to quickly find all the other hostnames associated with those IPs:
sqlite> select * from ip_hostname where ip='104.18.12.238';104.18.12.238|alert.co.za104.18.12.238|dev-api.alert.co.za104.18.12.238|east-rand.staging.alert.co.za104.18.12.238|johannesburg.staging.alert.co.za104.18.12.238|staging.alert.co.za104.18.12.238|www.alert.co.za104.18.12.238|advancedwindowsystemsllc.com104.18.12.238|adbox004.com104.18.12.238|exitwidget-id.com104.18.12.238|www.exitwidget-id.com104.18.12.238|api.ext.fourthline.com104.18.12.238|mapi.ext.fourthline.com...The results above have been truncated because Shodan uses Cloudflare as its CDN so there are a lot of other websites with the same public IP.
Banners
We are introducing 2 new datasets that contain the same data as raw-daily but in a different format and timeframe:
banners-dailybanners-hourly
The banners-daily dataset is the same as raw-daily but it uses Zstandard for compression instead of Gzip. This means that the file sizes are smaller and they're faster to decompress:
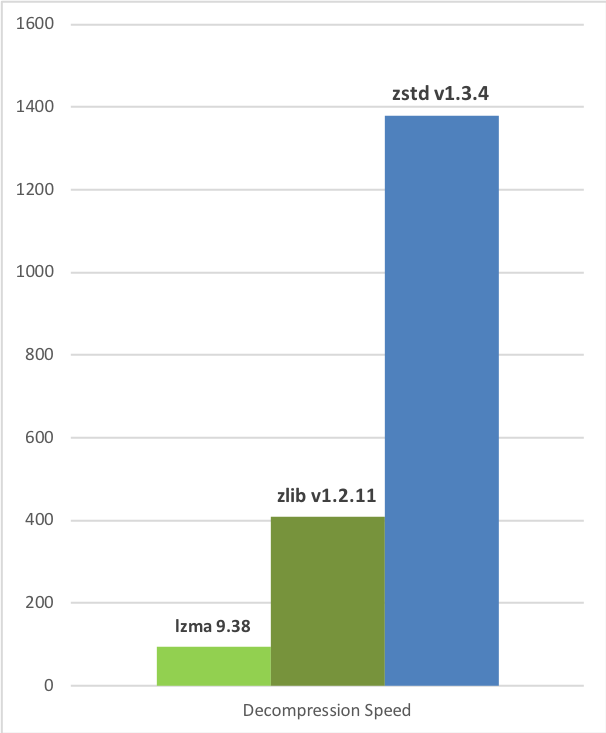
The banners-hourly dataset contains the same banners as banners-daily or raw-daily but the files are generated once an hour. I.e. every file contains all the information that has been gathered the past hour. We are offering these files as an alternative to the firehose for customers that are unable to consume the firehose or prefer to process data files. The hourly files mean that you're not far behind the firehose (at most an hour), they're fast to download/ process and if there were any issues with the firehose then you can use the hourly files to fill in any gaps in data. The banners-hourly files are also compressed using Zstandard.
RoutesDB
The routesdb dataset contains a MMDB database that can be used to lookup routing information about IPs such as its ASN, prefixes (v4 and v6) for the ASN, peers and other related information about the organization that is managing the IP.
The mmdblookup tool from MaxMind can be used to lookup IPs without having to write any code. For example:
$ mmdblookup -f routesdb.mmdb -i 1.1.1.0
{ "asn": 13335 <uint16> "source": "ARIN" <utf8_string> "info": { "descr": [ "Cloudflare, Inc." <utf8_string> "101 Townsend Street, San Francisco, California 94107, US" <utf8_string> "+1-650-319-8930" <utf8_string> ] "mnt-by": [ "MNT-CLOUD14" <utf8_string> ] } "prefixes_v4": [ "1.0.0.0/24" <utf8_string> "1.1.1.0/24" <utf8_string> "8.6.112.0/24" <utf8_string> "8.6.144.0/23" <utf8_string> "8.6.146.0/24" <utf8_string> "8.9.231.0/24" <utf8_string> Quickstart
shodan data download routesdb routesdb.mmdb.zst \ && zstd -d routesdb-routesdb.mmdb.zst \ && mv routesdb-routesdb.mmdb routesdb.mmdbIf you're running Ubuntu then you can install the mmdblookup tool using:
apt install -y mmdb-bin
EntityDB
The entitydb dataset contains a SQLite database of financial data on public companies derived from SEC filings combined with DNS and ASN information. It's built quarterly and powers the EntityDB API.
Quickstart
shodan data download entitydb entity.sqlite.bz2 \ && mv entitydb-entity.sqlite.bz2 entitydb.sqlite.bz2 \ && bunzip2 entitydb.sqlite.bz2Example: Lookup information about Apple
sqlite> select * from entity where entity_name='Apple Inc.';1|www.apple.com|320193|operating|Apple Inc.|3571|Electronic Computers|["AAPL"]|["NASDAQ"]|942404110|0928|CA|ONE APPLE PARK WAY, CUPERTINO, CA, 95014, CA|ONE APPLE PARK WAY, CUPERTINO, CA, 95014, CA|(408) 996-1010|{"alias": ["APPLE INC", "Apple Computer Trading (Shanghai) Co. Ltd.", "APPLE DISTRIBUTION INTERNATIONAL LTD.", "Apple Inc."], "domain": ["apple.com", "itunes.com"]}|2024-05-29 21:55:00
InternetDB
We now generate the InternetDB SQLite file once a day.
Thoughts, suggestions or other feedback? Let us know